Manual curation is vital for maintaining quality information in biological databases. However, with the exponential growth in biological data this approach is both challenging and time consuming. We wanted to create a scalable and sustainable process which could complement manual curation.
We recently launched a new service – SciLite – that allows text-mined annotations to be displayed on research articles. The aim of this effort is to promote sustainability of curated databases by bridging the gap between literature and data. To this end, SciLite:
We recently launched a new service – SciLite – that allows text-mined annotations to be displayed on research articles. The aim of this effort is to promote sustainability of curated databases by bridging the gap between literature and data. To this end, SciLite:
- supports database curation processes, by highlighting biological concepts, making it easier to find key concepts described in articles;
- provides a mechanism to link those concepts to the related resources, for efficient data integration.
SciLite’s open design enables community-driven annotations, from text-mining groups, and manual annotations, to be made available to Europe PMC users.
What are SciLite annotations?
SciLite annotations enable biological terms and concepts, such as genes/proteins, diseases, organisms and accession numbers, to be highlighted on full text articles in Europe PMC. Using the check-boxes on the right-hand side of article pages, readers can select the types of concepts that they are most interested in and matching annotations for that article will be highlighted on the article text as below.

Clicking on the highlighted terms in the text opens a popup with a link to related database record. In the example below, an interactive Protein Data Bank (PDB) structure model is also provided when you click on a highlighted PDB accession number.
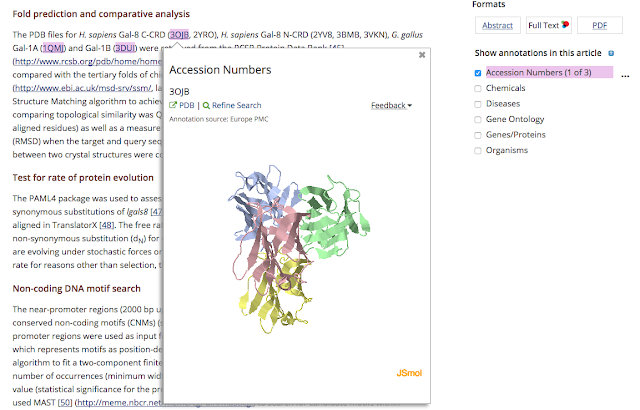
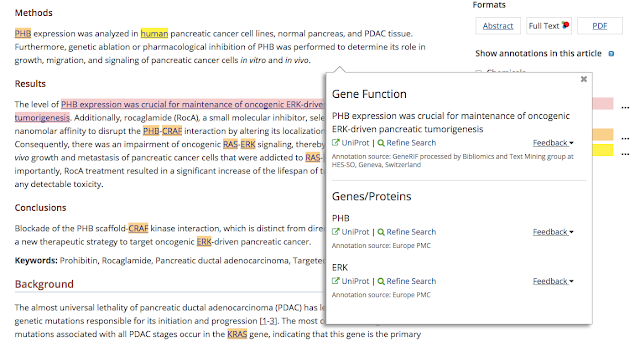
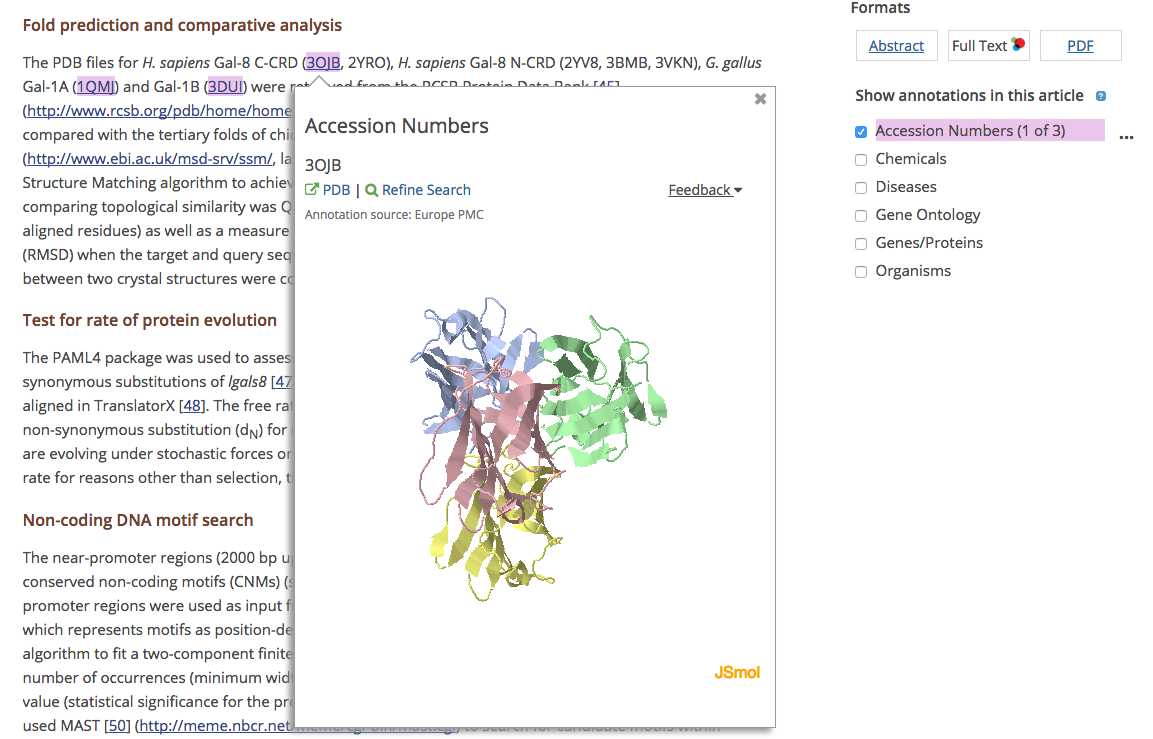
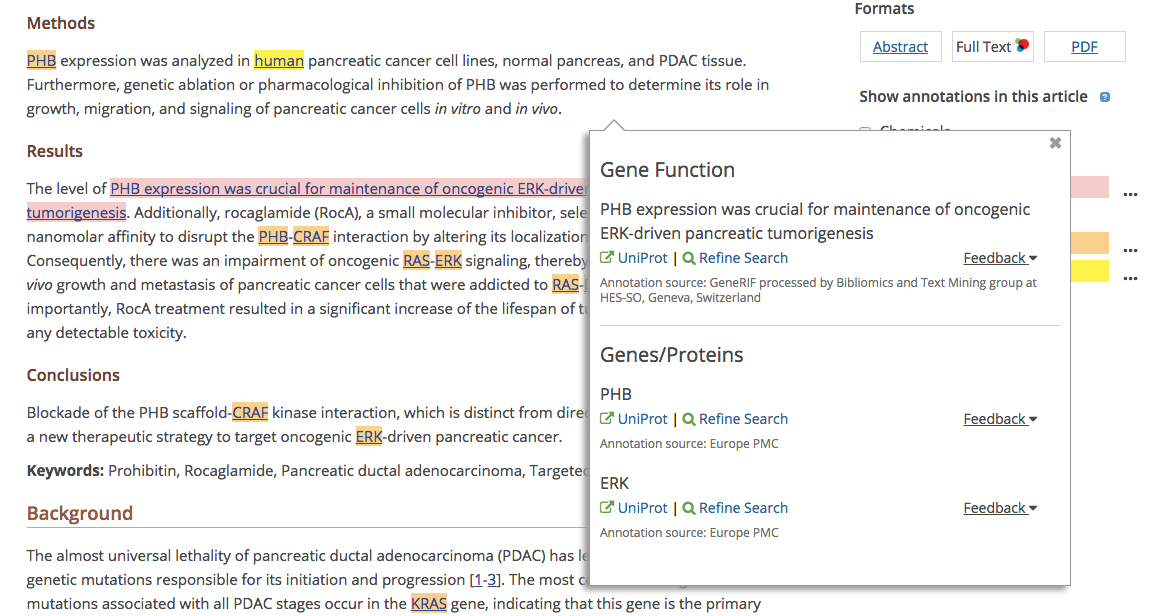
When annotations are provided by the text-mining community, the source of the annotation is displayed. In the example below, the Gene Reference into Function (GeneRIF) annotations were provided by the Text Mining group at HES-SO, Geneva, Switzerland.
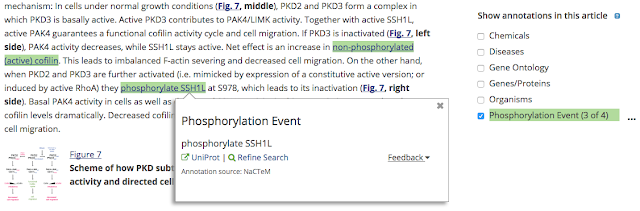
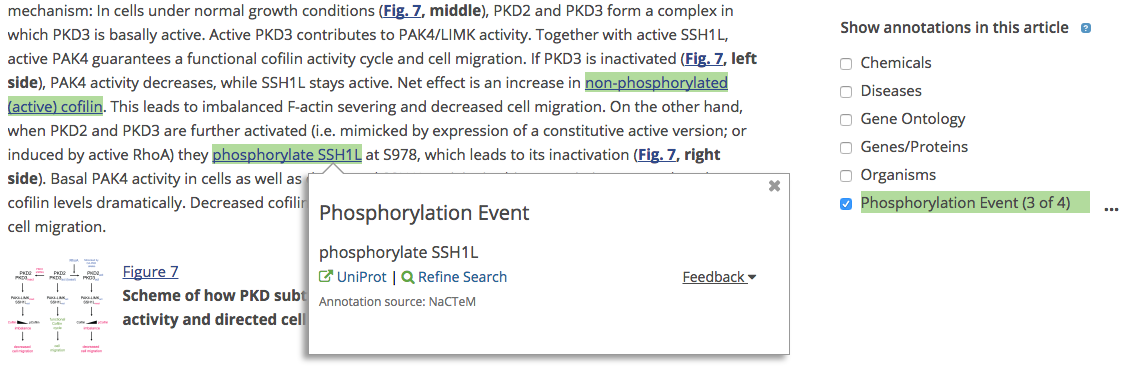
Another text-mining group – NaCTeM – has provided phosphorylation event annotations, as shown below.
Take a look at this example article with annotations.
Annotations are displayed on articles with a CC-BY, CC-BY-NC or CC-0 license.
How are annotations generated?
The biological terms and concepts are identified by text mining algorithms, which are developed by a variety of text mining groups. Any text-mining group can participate in this scheme. Once concepts of interest have been identified within the text, they are formatted according to the W3C Web Annotation Data Model, and stored in a triple store via the EMBL-EBI RDF Platform. If you are a text miner, find out how to provide annotations to Europe PMC at our SciLite annotations page.
We’re improving annotations with your help
Because annotations are generated automatically by text mining algorithms, we want to ensure that annotations are useful to users of Europe PMC. On each annotation there is the opportunity to provide feedback by either marking the annotation as incorrect, or endorsing useful annotations.

This information is fed back to the Europe PMC team and will be acted upon, helping to improve the annotations overall.


