Europe PubMed Central (Europe PMC) is an open access repository of life science research, including peer-reviewed journal articles and preprints. It contains over 41 million abstracts and 8.7 million full-text articles, adding over 1.7 million new articles annually. To facilitate information discovery and foster literature–data integration, Europe PMC has incorporated text-mining approaches into its workflows.
Text-mining is a powerful tool used in the field of biomedicine to extract relevant information from large amounts of text data, such as research papers, clinical reports, and patient records. It involves using machine learning algorithms and natural language processing techniques to identify key concepts and relationships between words and phrases in the text.
With millions of new research papers published every year, it’s impossible for researchers to read and synthesise all of the information available manually. Text-mining algorithms can be used to automatically extract key concepts, relationships, and findings from scientific papers, allowing researchers to quickly identify relevant information and stay up-to-date on the latest developments in their field.
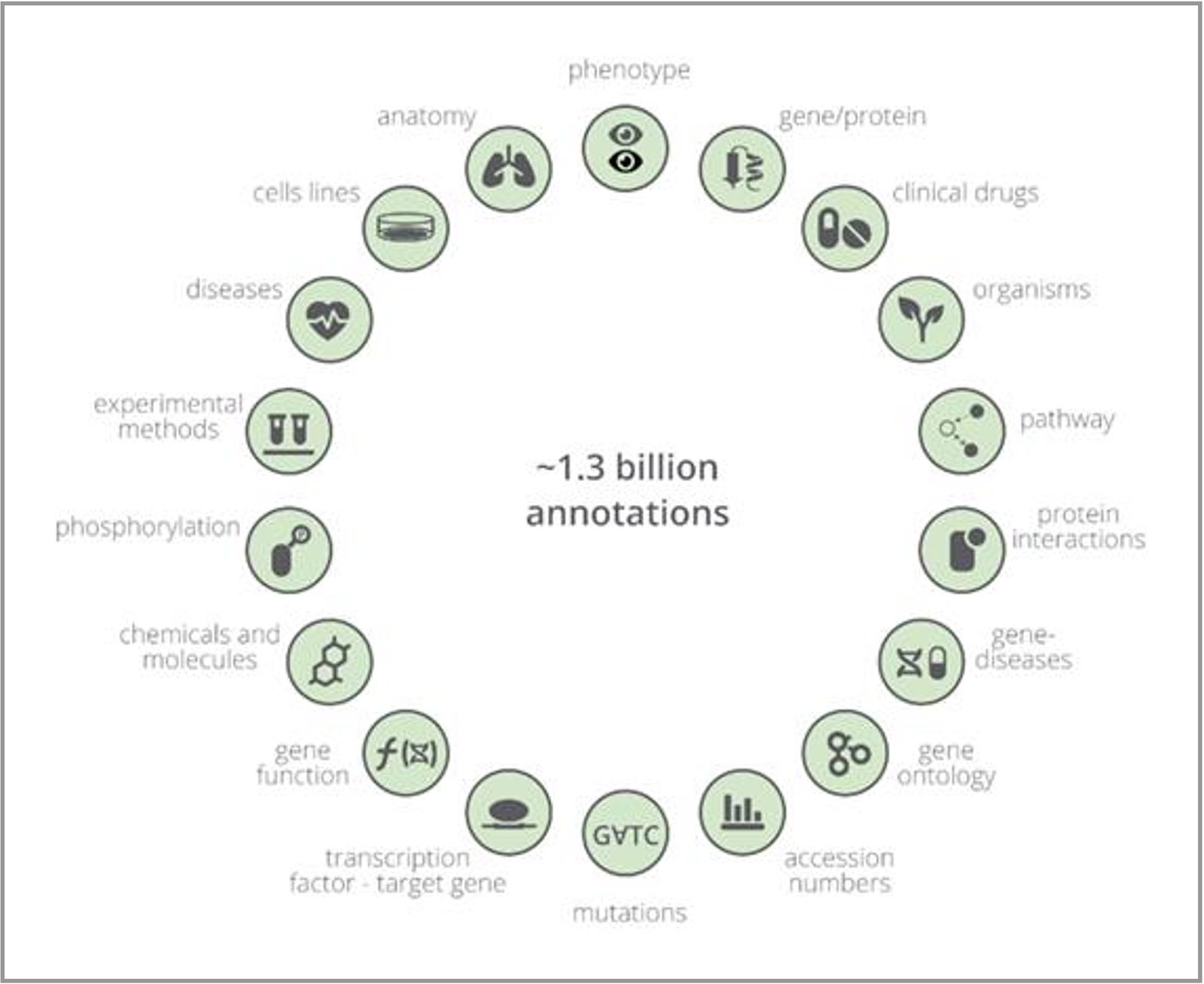
At Europe PMC, the SciLite Annotations tool uses text-mining to highlight terms in research articles and preprints, allowing users to quickly scan the article for relevant concepts, such as diseases, chemicals, or protein interactions. Europe PMC contains ∼1.3 billion annotations sourced in-house and from 10 external providers. The annotations platform covers multiple annotations types including bioentities ranging from accession numbers to Open Targets gene–disease relationships. Users can programmatically access the annotations using the Annotations API, reducing the time requirement of extracting facts and evidence to help advance the discovery process.
How Europe PMC developed annotations for named entities
Europe PMC has developed annotations for Gene/Protein, Disease, Organism and Chemical bioentities. For this purpose, established ontologies are being used as dictionaries to pattern match the entity-terms from the text. For example, the Unified Medical Language System (UMLS) ontology is used for tagging diseases mentioned in articles. Although the dictionary-based approach is easy to understand and to implement, an exhaustive list of patterns are required to recall more entities and require regular updating to remain current. Moreover, with the contextual information missing, this creates ambiguity, especially with the use of acronyms and abbreviations by scientists writing papers. For example,Cockayne syndrome Group A and Corporate Social Responsibility are both abbreviated to CSA. Overall, this approach has multiple challenges, which cause false positives, false negatives, and other technical issues, as listed below:
False positives
Short target names are confused with ambiguous abbreviations.
- Cockayne syndrome Group A (CSA) vs Corporate Social Responsibility (CSA)
Contextual differences to identify terms
- Hearing (aids) vs AIDS the disease
Common English words
- CAN gene vs ‘can’ being a common English word
Multiple entities or mentions of compound entity
- It is difficult to pattern match BRCA1 and 2 or BRCA1/2 vs BRCA1 and BRCA2
False negatives
Missing of entities that do not exist in the original ontology/dictionaries
- E.g., T2D for Type 2 Diabetes Mellitus
- The ontology shall be updated regularly to keep up with the growing literature
Technical issues
Encoding issues often create garbage values when converted from ascii to UTF-8 format
- TNFα vs TNFα
Sentence boundary problems
- It is difficult to delineate a sentence within a caption of a Figure or a Table

Challenges faced when using a dictionary-based approach to annotate entities in scientific text including false positives, ambiguity of abbreviations, special characters, and a lack of distinction between genes and proteins.
Improving annotations using machine learning: gold standard dataset
To address the challenges of using a dictionary-based approach to annotations the Data Science team at Europe PMC has explored the use of machine/deep learning techniques.
To train any machine-learning algorithm, a gold standard dataset of annotations is needed. While corpora without annotations are good for learning semantics, text-mining tools trained on human-annotated corpora outperform those trained on non-annotated ones. Therefore, open-source gold-standard datasets are crucial for improving biomedical text-mining systems. Based on this information, the team methodologically developed an annotated full-text corpus based on annotation guidelines. The corpus is a collection of 300 research articles from the Europe PMC open access subset. The selected articles have been annotated by humans to indicate mentions of three biomedical concepts: Gene/Protein, Disease, and Organism. The annotation guidelines were used by the human annotators to select the correct text span and type of annotation.
Problems faced while developing the gold standard dataset
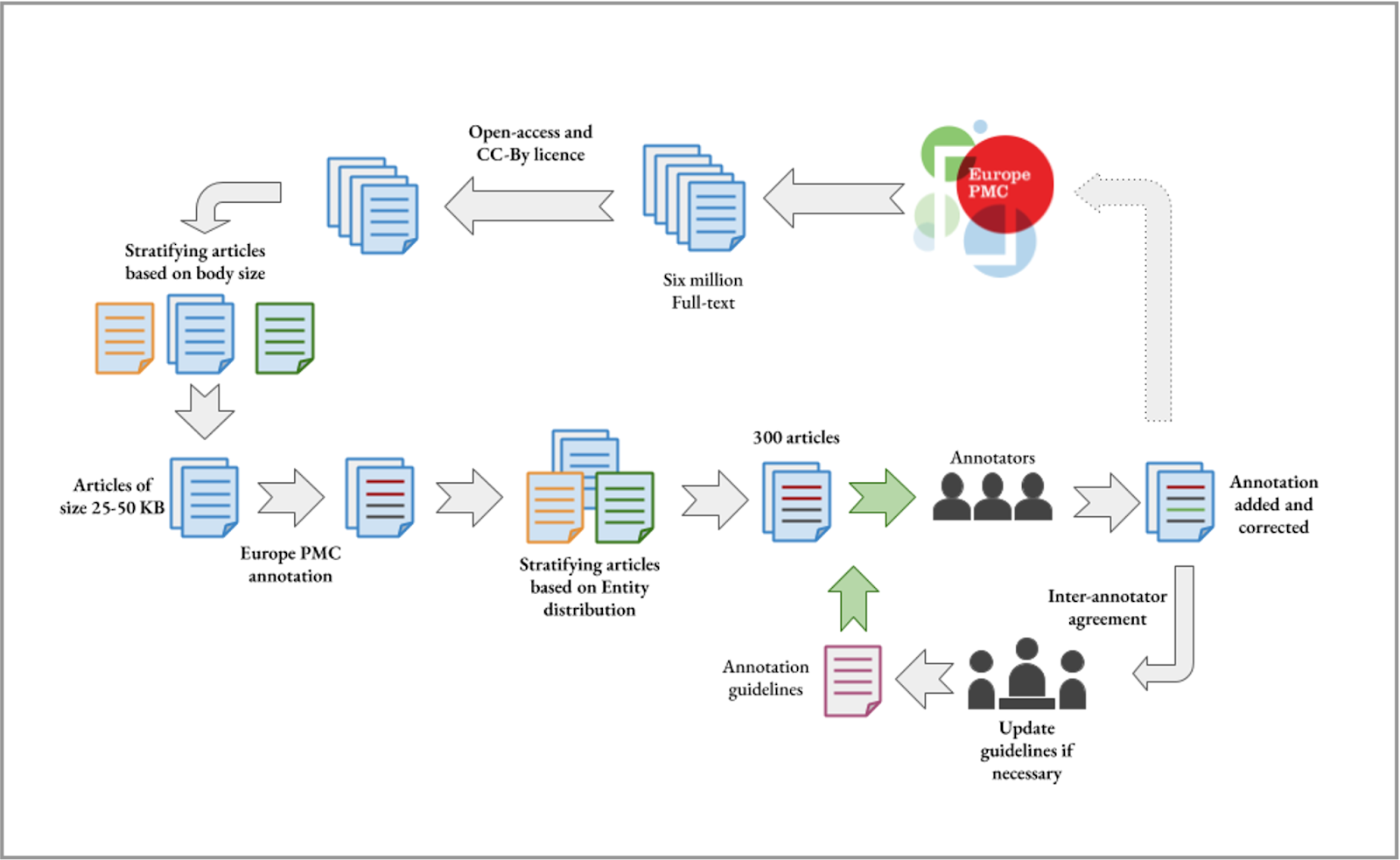
The Europe PMC team faced several challenges in creating a gold standard training set to support machine learning approaches for entity extraction. One of the first hurdles was to select a small number of representative articles from the several million available in the Europe PMC database. For this purpose a strategy was designed and several techniques were employed to stratify articles and select the representative set.
Out of approximately 6 million full-text articles in the Europe PMC repository, archived on the 31st of August, 2018 (v2018.09), approximately 1 million were open access with a creative commons licence and could be included in the training set. The training set was further refined by the following criteria: article sizes between 25 and 50 KB were selected, which resulted in a collection of approximately 0.5 million articles. This was followed by sorting the articles with the entity mentions into low, medium, and high ‘bins’ for each entity type, that is Gene/Protein, Disease, and Organisms. Articles containing small or no mentions of any of the entities were discarded, leaving over 460,000 articles of which 300 were randomly selected. The final stage of the strategic workflow included working with the annotators iteratively to improve the annotation guidelines.
Collaborating with Molecular Connections to annotate the corpus
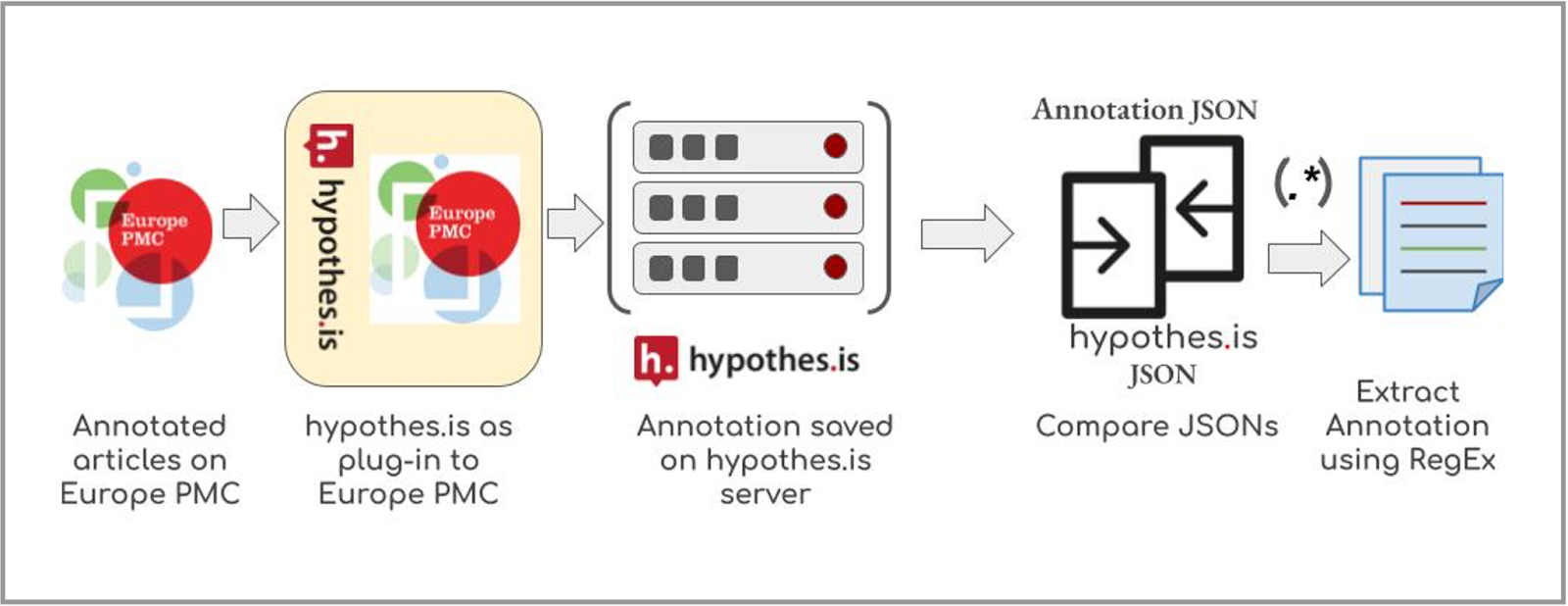
Europe PMC collaborated with Molecular Connections to annotate the corpus. The annotators were asked to use the hypothes.is tool, which was added onto Europe PMC as a plug-in to support collaborative efforts for the annotation work. Annotators saved their annotations to the hypothes.is server in JSON format, which was retrieved and converted to CSV format using in-house tools. This project used a triple-anonymous approach to annotation; three annotators annotated the same articles independently to ensure annotation quality and validate inter-annotation agreement. Annotation discrepancies were resolved by the majority vote to achieve/ensure the best quality annotation. That is, at least two annotators must agree on the annotation boundary and the entity type of the entity terms to pass the acceptance threshold. This maximised the total number of annotations. For example, if one annotator misses a term, it will likely be picked by the two other annotators. The triple-anonymous method made it possible to conveniently assess the inter-annotator agreements to ensure the annotation quality. Using this approach, we were able to increase the annotations’ accuracy from 70% to 99%.
What can you do with the Europe PMC open source corpus?
The Europe PMC Annotations Corpus is among the largest human-annotated biomedical corpora publicly available. The corpus also comes with scripts that were used to clean and format the annotations from the Hypothes.is platform. The dataset is also available in the IOB format for input to deep learning algorithms. In addition, the annotation guidelines are also made available for researchers to improve/compare conclusions drawn from the results.
This open source gold-standard dataset can be used to improve the accuracy and reliability of life science natural language processing tools such as entity recognition, supporting advancements in scientific research. Furthermore, the corpus can support clinical decision-making by providing access to relevant clinical information that can be used to develop clinical decision support systems, which could improve patient outcomes and reduce healthcare costs.
The Annotated Corpus can accelerate life science research by providing large amounts of accurately labelled data that can be used to train machine learning models for various applications, including drug discovery and disease diagnosis. For example, the deep learning models that were trained using the Europe PMC Annotations Corpus are now being used for literature mining for Open Targets to identify and prioritise drug targets, provide evidence for drug target validation, and support drug repurposing efforts to accelerate and improve the efficiency of drug development.
To find out more about the Europe PMC Annotations Corpus and details on how to access and reuse this open community resource:
- View webinar recording: https://bit.ly/MLWebinarReg
- Read the preprint: Europe PMC Annotated Full-text Corpus for Gene/Proteins, Diseases and Organisms
Written by Santosh Tirunagari, Senior Machine Learning Developer at EMBL-EBI


