Software powers modern research across many scientific disciplines, but it’s often hidden in plain sight, buried as unstructured text within the article body. This means that often software is difficult to identify and track in scholarly publications. SoFAIR is a project dedicated to automatically extracting software mentions from scientific literature. Enriching publications with this metadata represents a crucial first step toward treating software as a first-class bibliographic entry.
As a demonstrator use case, we used the Europe PMC corpus of approximately 70,000 full text preprints, which have been converted from PDF to XML. This corpus is composed of two subsets – approximately 50,000 COVID-19 preprints from a now completed project, and the remainder funded by Europe PMC funders as part of an ongoing initiative.
We processed the corpus using the following pipeline.
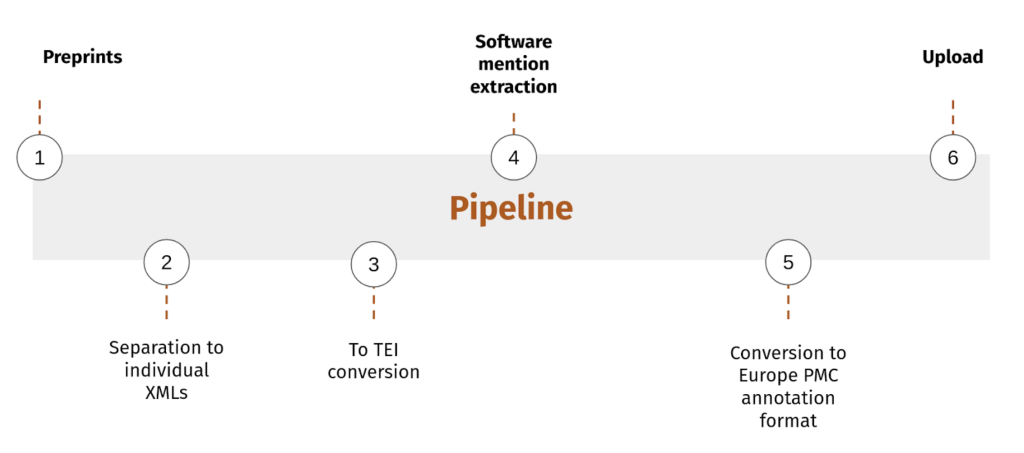
The corpus is in JATS XML format, which we converted into TEI using the Pub2TEI converter. We performed this conversion because we needed a compatible format for Softcite, the software mention extraction tool used in this project. We then ran the extraction and obtained 1,099,332 software mentions (counting all mentions, not unique software names), originating from 52,684 publications, covering nearly 78% of the corpus.
To integrate our results with Europe PMC, we converted the extracted mentions into the Europe PMC annotation format, following the official submission guidelines. Each annotation includes standard fields such as the article source and identifier, the provider name (SoFAIR), and a list of annotations. For each software mention, we supply the exact text span, its surrounding context (prefix and postfix), entity name, and a URI, where available.
The most challenging part of our work is the mandatory URI field, as not every extracted software mention has an associated URL or other identifier. Out of the 1,099,332 software mentions, only 12,272 (1.12%) were found in 1,694 documents (2.50%) to have a valid URL to serve as URI.
To mitigate this problem, we added an extra post-processing step to extract URLs from the immediate context surrounding a software mention. It links a URL to a software mention only when the URL contains the given mention as a case-insensitive substring. We performed a manual evaluation of a subset of 50 URLS and found that 49/50 URLs were correct. After this step, the number of software mentions with URL increased to 37,014 (3.37%), which corresponds to 8,616 (12.71%) documents with at least one software mention.
The SoFAIR annotations have been uploaded to Europe PMC and are publicly available via the Europe PMC Annotations API. This integration is immediately useful to users, as it allows them to retrieve information about the software used in scientific papers. For example, you can use the following API call to list available mentions: https://www.ebi.ac.uk/europepmc/annotations_api/annotationsByProvider?provider=SoFAIR&filter=1&format=JSON&pageSize=4.
Looking ahead, the Europe PMC team aims to make these software mentions visible and searchable on the website, enhancing discoverability. By enriching the literature with software metadata, this work strengthens transparency, reproducibility, and traceability, supporting software as an essential first-class bibliographic entry.
Written by guest author Martin Dočekal.


